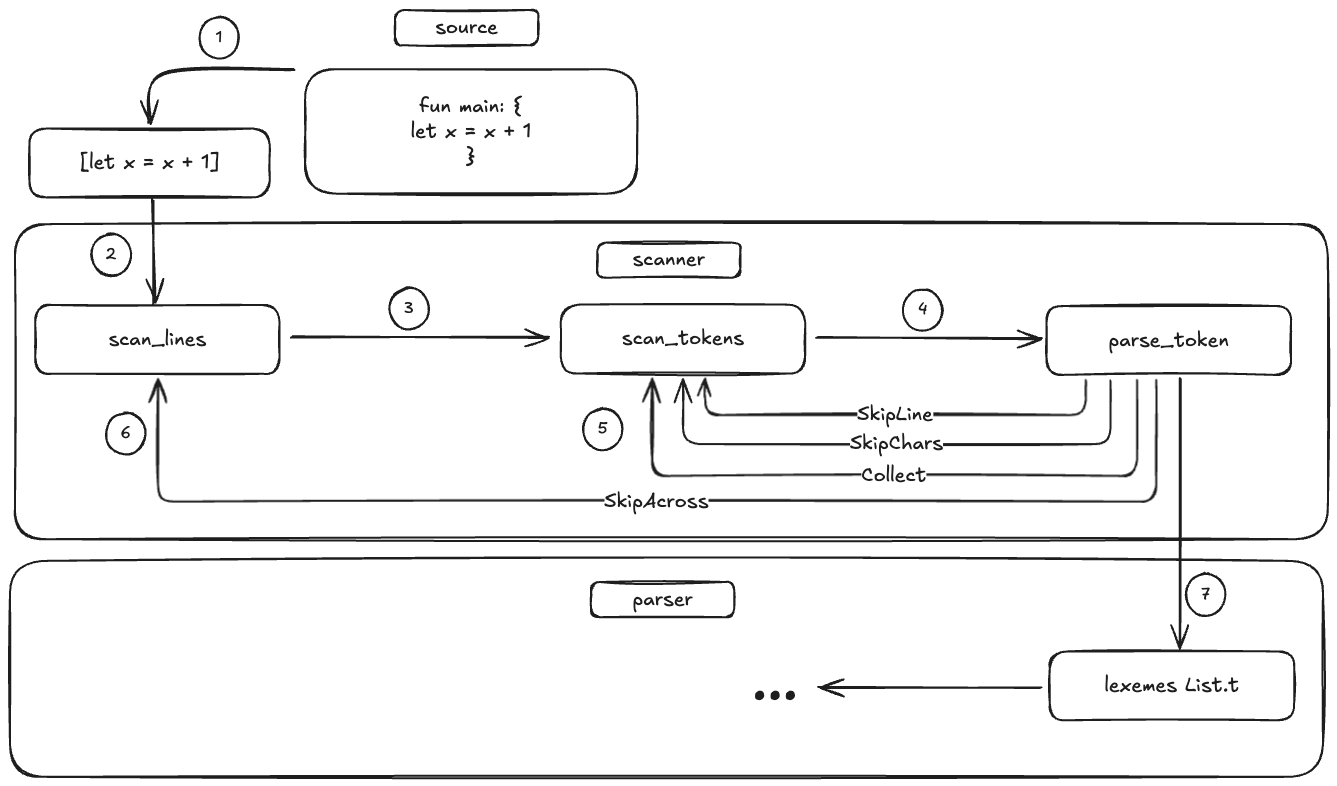
I made the leap to start going through the Crafting Interpreters book. Rather than use Java or C as in the book, im pivoting to use Ocaml and Rust for the project and interpreter. This lead me to an interesting use case for using OCamls effects system to handle an issue I experienced.
Lexing
In brief, lexing is a functions from strings to tokens. A lexer or scanner will typically take in a string of characters from the source file to a sequence of tokens which can be easily interpreted by the later stages (i.e parser).
creating the stream
We first need to convert our source file into a stream of characters or strings. An extra feature not part of the book is to make our lexer lazy. We can accomplish this by using Ocamls Seq - We can easily read a file into a stream using the Seq.of_dispenser function which creates a non-persistent stream (i.e can only be used once - in order to use it multiple times, you can pipe through Seq.memoize)
let fopen filename =
let ic = open_in filename in
Seq.of_dispenser (fun () -> In_channel.input_line ic)
;;
In this case, we are reading line by line from the source file. We can then map each line to its line number for easy debugging. We can then simply convert each line into a sequence of characters in order to parse token by token.
let scan_lines lineseq =
(* zip with line numbers - start count from 1 *)
let lseq = (Seq.zip lineseq (Seq.ints 1)) in
let rec lines lseq state =
match Seq.uncons lseq with
| Some ((line, num), more) ->
let lexemes = scan_tokens more (line |> String.to_seq) in
(match lexemes with
| Ok lexemes' ->
let state' = Ok (num, lexemes') :: state in
lines more state'
| Error e ->
let state' = Error (num, e) :: state in
lines more state'
)
| None ->
List.rev state
in lines lseq []
;;
Then we can handle each character by matching it into a token
let scan_tokens lines charseq =
(* zip with col numbers *)
let cseq = (Seq.zip charseq (Seq.ints 0)) in
let rec chars lines cseq state =
match Seq.uncons cseq with
| None ->
Ok (List.rev state)
| Some ((tok, col), more) ->
let (lexeme', lines', more') = parse_token tok lines more in
match lexeme' with
| Ok NONPERT ->
chars lines' (more') (state)
| Ok MULTILINECOMMENT ->
chars lines' (more') (state)
| Ok lexeme ->
chars lines' (more') ((Token.mktoken lexeme col) :: state)
| Error _ as e ->
e
in chars lines cseq []
;;
So far its worth noting that we are using a functional approach and passing the current sequence to the parse_token function in case we need to advance the cursor on the current line. that way if we modify the state we pass it back to the previous function so that it has the latest position.
The tricky part comes when we are handling each token and we need a way to advances the buffer or sequence of tokens so that we can handle complex patterns even ignore unneeded patterns. Take for example we need to handle a C style single line comment.
TO BE CONTINUED ... ← Back to all articles
Comments